잠시 학부 연구생 관련해서 좀 신경을 쓸게 있어서 늦어졌지만, 다시 프로젝트를 진행했다. 이번에는 결과가 꽤 좋다. 다만 이렇게 보니 생각을 해야 할게 더 많아졌다는 느낌은 있다. 그래도 괜찮다. 데이터를 모으고 효율적인 형태로 두는 것 정도는 자신이 있었는데, 작지만 성과가 생기니 기쁘다.
이제 본격적으로 내가 할 일에 대해서 기록을 남겨두고자 한다. 이전에는 글로 기록하지 않아서 문제가 생겼으면, 개선을 해야지 사람일 것이다. 보니까 이전 글에 내가 무슨 데이터를 모으고 있는지 그 어느 것도... 정말 아! 무! 것! 도! 적어두지 않았다. 새해니까 머리를 식히고 가야 할 것 같다.
모은 데이터는 TRC-20, 그러니까 Tron이라 불리는 블록체인 네트워크의 특정 컨트랙트에 관한 기록이다. 이렇게 이야기하면 거창해 보이는지 모르겠는데, 정말 간단하게 이야기하면 송금기록이다.
Tron은 내가 주목하고 있는 네트워크 중 하나이다. 최근에는 강력한 경쟁자가 생기기는 했다고 하지만, 여전히 테더 스테이블 코인에 대한 점유율은 높고, 내 휴리스틱이나 가설을 검증하기에 이 네트워크가 훨씬 좋을 것 같아서 선정했다. 차후에는 언급했던 강력한 경쟁자인 Solana에 대한 것도 분석을 비슷하게 진행해 볼 것이고, 그것에 대한 예행연습이자 포트폴리오가 이번 프로젝트이다.
앞에서 모은 데이터는, USDT, 소위 테더라 불리는 스테이블 코인에 관한 송금 데이터이다. 테크니컬한 이야기를 없애면, 어떤 주소가, 어떤 주소에게, 얼마만큼, 언제 보냈는가에 대한 간단한 정보가 1개의 data row가 될 것이다. 여기에 어떤 transaction id 인지, event index는 어떤지, 해당 tx가 포함된 블록 넘버는 뭔지 같은 잡다한 정보정도만 추가하면 실제로 내가 저장한 데이터와 크게 다를 바도 없다.
이런 데이터를 모아서 뭐할 거냐고 물어보면, ML, 머신러닝하는데 써볼 계획이다.
1. 송금 데이터는 네트워크 구조 형식의 자료이다.
송신 주소와 수신 주소를 vertex(정점)이라 보면, 내가 모든 데이터는 그 정점을 잇는 edge, 즉 graph자료라고 생각할 수 있다. 이러한 경우 네트워크 분석을 곁들일 수도 있고, amount에 적절한 처리를 한다면 실제로 clustering 하기도 용이할 가능성이 있다.
2. 송금 데이터는 time-series 자료이다.
송금은 시계열 데이터이다. 이건 특별한 설명이 없어도 납득할 것이다. 누가 "언제" 보냈는가 에 대한 정보가 송금 정보에 포함되어 있고, 이것이 반복된다면 어떠한 패턴을 찾을 수 있을 수도 있다. 간단한 SARIMA 같은 걸 적용해 보는 것도 좋은 훈련이 될 것이다.
그래서 이 프로젝트 한번이면 네트워크 분석은 물론 시계열 분석도 같이 해볼 수도, 학습할 수도 있다. 난 좋은 기회라고 보기도 하지만 흥미가 있어서 꼭 배우고 싶다.
다만 분석에 대한 내 방법론, 포커스는 신경망... 같은 쪽은 아니다. RNN이 이런 구조에 정말 적합하긴 하겠는데, 지금은 딥러닝을 통한 분석은 일부러 배제하고 있다. 이유는 :
1. Explainablilty가 여전히 부족한 현실
이것도 말이 거창하지 내가 제어할 수 없다는 이유가 더 크다. ANN이 어떻게 예측을 했다고 쳐도 그게 왜 그런 건지, 뭘 배운 건지 뭐 하나 쉽게 가르쳐주지 않는 것이 딥러닝이다. 나는 딥러닝에 대해 배우고, 열심히 모델을 증진시켜야 하지만, 솔직히 이렇게 해서 내 직관이 향상될지는 잘 모르겠다.
2. 고전적 ML에 관한 흥미
앞의 이야기의 연장선으로, 기존의 ML은 어느 정도 확률론이나 수학 등으로 커버가 되거나 뒷받침하는 가설도 있기 마련이다. Linear Regression은 이야기할 것도 없이 꽤나 연구가 되어있고, 나는 그런 식으로 내 지식이 느슨하게나마 수학과 연계되는 쪽을 선호한다.
3. Cost
비싸다. 그래픽카드는 하늘에서 떨어지지 않고, 전력도 마찬가지다.
4. 석사 학위에 대한 거부감
나중에 좀 자리를 잡으면 공부를 해볼 수도 있겠지만, 나는 개인적으로는 석사에 흥미는 없다. 뭐 이전부터 학위에 딱히 흥미는 없었다. 심지어는 대학도 마찬가지고. 그렇지만 대학은 한국에서 안 나왔다간 좀 뭐 할 가능성이 있으므로 일단 다닌다 쳐도, 석사까지 해서 몇 년을 더 버려야 하는 게 마음에 안 든다. 난 개인의 소득은 빠르게 얻을수록 좋다고 생각한다. 물론 그렇다고 알바를 매년 해서 먹고살 수는 없을 테니 일단 직장은 구해야 할 텐데, 딥러닝을 내가 "잘한다"라고 입증을 하려면 어느 정도는 석사 이상의 학위가 있을 필요성이 있을 것이고, 연구직은 더 그럴 것이다. 난 그러한 학위를 구하고 싶지도 않고, 구할 여유도 없다고 생각한다.
그!래!서! 일단 고전적인 ML 모델을 집어넣어서 뭘 해볼 것인가? 난 이 주소는 "이런 역할", 이라는 의미의 Classification을 해보고 싶다. Tron에서 각기 주소가 주로 어떤 역할을 맡더라~ 뭐 이런 것을 알려주는 모델을 만들고자 한다. Energy Seller, Tether Transporter, Tronnet User, 지금은 크게 주요 클래스를 3개 정도 보고 있고, 필요에 따라서 추가할 수도 있다. 각기 역할은
1. Energy Seller
Tron을 네트워크 프로토콜에 따라 Stake 하고 거기서 나오는 Energy를 임대해 주고 TRX를 받는 역할
2. Tether Transporter
1.로 부터 산 Energy와 Bandwidth 등으로 Tether를 송금해 주는 Smart Contractor
3. Tronnet User
2. 가 제공해 주는 서비스를 이용해 주는 주요 네트워크 수요 고객층
이다. 이건 final한건 아니고 일단 내가 생각하기에는 이렇다는 것이고, 한번 분석을 해보고 나중에 적절히 수정할 것이다.
아무튼, ML 쪽으로는 여기까지 진행해 보는 게 중간 목표이다.
마지막은 내가 위에서 정제한 자료들을 이용해서 적당히 깔끔한 UI로 웹사이트를 1개 만들 수 있으면 끝이다. 이건 Next.js를 이용해서 간단히 진행할 예정이다. 마침 보안사고도 얼마 전에 터져서 오히려 편하게 이용할 수 있을 것으로 보인다. js는 많이 다뤄보기도 했지만, 여기에는 뭐 엄청난 노력을 기울이지는 않을 것이다. 결국 위가 본체니까.
이런 거창한 목표를 위해서는 당연히 밑바탕이 되는 데이터가 필요하고, 그걸 위해서 오늘까지 해온 것과 결과를 정리할 것이다.
일단 지난번에는 provider가 지속적으로 데이터를 제공 가능한가, 그리고 얼마나 빠르게 모을 수 있는가를 보았다. 큰 문제1은 내가 이 시계열 데이터를 그냥 raw 하게 저장하는걸 SQLite3에 넣었는데, SQLite3는 기본적으로 Thread-Safe 하지 않고 그렇게 DB로써 좋은 설루션은 아니라는 것이다. 큰 문제 2는 TronGrid의 일일 API request 전체 capacity 소비가 안된다는 점이다. 하루에 리퀘스트를 10만 건까지 무료로 보낼 수 있는데 정작 그만큼 보내지도 못한다는 게 말이나 되는 소리인가...
문제 1. 더 탄탄한 저장 솔루션 찾기
이건 문제를 잘 파악하면 충분히 해결 가능한 문제였다. 일단 데이터 특성상, 수집을 시작하기 시작하면 데이터가 엄청 쌓인다. 실제로, 내가 간단히 테스트를 했을 때 쌓이는 초당 tx의 개수가 600개 언저리께였으니, 그 정도의 부하를 견딜 수 있는 데이터 베이스 구축이 필요하다. 그런 와중에 file-based db를 쓴다는 것은 그다지 좋은 생각은 아니라고 보았다. 내가 ML을 돌리려면 당연히 데이터를 정제된 상태로도 들고 있어야 한다. 즉, 2차 가공이 필요한데, 이것도 같이 저장해야 한다.
즉 많은 양의 시계열 데이터에 대해 insert(copy) / select가 충분히 빠르고, ML에 쓰이기 좋은 형태로 가공하기 쉬운 데이터베이스가 있으면 좋다는 것이다. 이를 내가 맨날 쓰는 db인 PostgreSQL에 time-partition을 적용해서 쓰는 것도 방법이다. 그렇지만 난 이 문제를 더더 쉽게 해결하는 방법 중 하나인, timescaleDB라는 PostgreSQL의 extension을 알고 있다. 뭐 원래부터 시계열 데이터하면 꽤나 유명한 확장 db이기도 하다.
설치는 간단히 docker로 진행하였다. 나의 mac은 그렇게 용량이 많지는 않아서 외장 ssd에 data를 연결해 mount 했는데, 굉장히 잘 먹혔다.
docker run -d --name timescaledb
-p 5433:5432
-e POSTGRES_PASSWORD=[설정할 비밀번호]
-v /Volumes/[원하는 외장 하드 경로]:/var/lib/postgresql/data
timescale/timescaledb:latest-pg16이렇게 하면 된다.
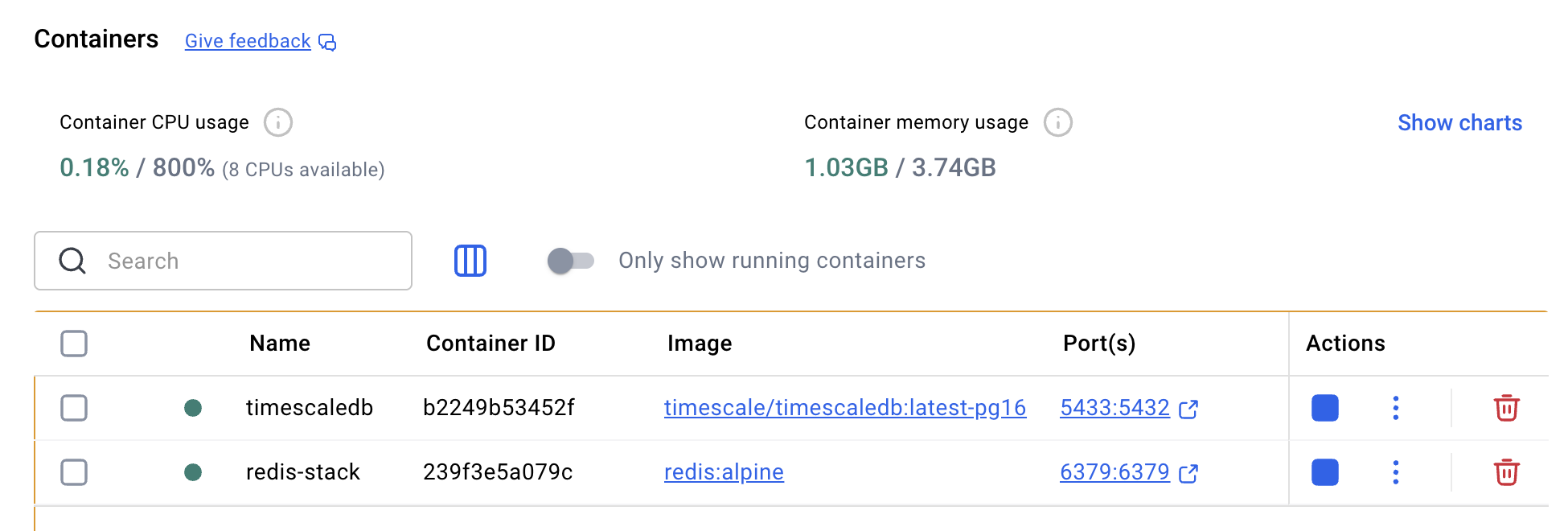
이렇게 하면 기본적으로는 PostgreSQL과 똑같지만 create_hypertable을 통해서 시계열 전용 hypertable을 만들 수 있다. 그럼 파티셔닝이나 이런저런 잡다한 것을 처리해 준다. 특! 히! 용량을 많이 줄일 수 있다.... 큰 데이터 셋을 분석해야 하지만 또 용량은 넉넉지 않은 내 상황에서는 좋은 기능이다.
아무튼... 이것 말고도 RAW데이터 보존을 위해서 parquet도 도입해서 백업 데이터도 챙겨두고 있는데, 이는 db는 아니고 그냥 파일 형태로 저장해 두는 것이다. 그래도 압축률이 꽤 좋기도 하고 이걸 도입함으로써 raw_usdt_transfer 테이블을 비워 성능 향상을 기대할 수 있다. (자세한 것은 아마 이것이 완성되면 나오는 아키텍처 관련된 설명에서 같이 할 것이다.)
문제 2. API 하루 용량 다 못쓰는 것 해결
이것은 async를 본격적으로 이용하면서 해결하였다. 다만 내가 데이터를 가져오는 단위를 임의로 20초로 잡았는데, 대충 3~4 request면 대부분 1 window를 가져올 수 있기 때문이다. 여기서 1000tx가 넘어 5개의 request를 전부 사용해도 안 되는 경우가 있는데, 이는 recursive 하게 timestamp 간격 사이의 데이터를 가져오는 메서드를 만들면 해결했다.
이 문제를 해결하는데 제일 재미있는 점은 어느 하나의 window에 대해서는 chain처럼 병렬 처리가 되지 않기 때문이다. 예를 들어 지금부터 20초간의 usdt송금 데이터를 가져온다고 해보자. 일단 원하는 window를 보내고 결과를 1번 받아야 한다. 이때 limit은 200이 최대이다. 즉 request 한 번당 200개를 가져오는 것이 최선이다. 위에서 보낸 request에는 fingerprint가 담겨 있고, 이는 다음 request에 보내 다음 200건의 데이터를 가져올 수 있는 티켓임과 동시에 재사용할 수 없다. 만약에 해당 window에 900개 정도의 tx가 있으면, 다음과 같은 과정을 반복해 900개의 tx 정보를 얻는다.
1. 최초 request 보냄 -> 200개 데이터와 fingerprint_1 받음
2. 2번째 request에 fingerprint_1 포함 보냄 -> 200개 데이터와 fingerprint_2 받음
3. 3번째 request에 fingerprint_2 포함 보냄 -> 200개 데이터와 fingerprint_3 받음
4. 4번째 request에 fingerprint_3 포함 보냄 -> 200개 데이터와 fingerprint_4 받음
5. 5번째 request에 fingerprint_4 포함 보냄 -> 100개 데이터 받음
이런 식이다. 그래서 무조건 1~5까지 순차적으로 request를 보내도록 되어있다는 것이다. naive 하게 request를 보내면 7만 건은커녕 하루에 5만 건 request를 보내기도 어렵다. 절반 가까이의 thuroghput을 날리는 셈인 것이다.

그래서 collection_task라는 추가적인 db형식의 queue를 만들어서 거기서 window와 관련된 사항을 관리하기로 했다. on-memory 하게 해도 되는데, 그럼 나중에 중단되었다 다시 시작해도 무결성 보장이 어려워지기에, 메모리에 있는 큐는 사용하지 않기로 했다. 아무튼 그렇게 병렬로 처리 가능한 async provider로 개조를 하고 나니 충분히 무료 api만큼 데이터를 가져올 수 있었다.
그래서 결과적으로는 이런 소득을 얻었다 :


약 6100만 건 정도의 송금 데이터를 얻었다. 아마 이 정도 양이면 나름 그래도 분석해볼 건더기는 있을 것으로 보인다. 이 구조를 그대로 확장해서 energy를 사고파는 행위에 대한 것도 대강 수집을 해볼 예정이고, 아직 부족한 부분에 대한 코드도 보강할 것이다.
'일지 > Proj4' 카테고리의 다른 글
| [QuakePot] Docker Desktop vs OrbStack(feat. edge-case block) (0) | 2026.01.31 |
|---|---|
| [QuakePot] 수집기 안정화 / 스스디 발열 잡기 (0) | 2026.01.27 |
| [QuakePot] 데이터 수집 asyncronous 문제 (0) | 2025.12.20 |


